
It’s Friday afternoon, the majority of the development staff has already packed up and headed home for the weekend, but you remain to see the latest hotfix through to production. To your dismay, immediately after deployment, queues start backing up and you begin to get alerts from your monitoring system. Something has been broken and all evidence points to an application performance bottleneck.

This experience is all too common for developers and software team managers. What can we do to prevent poor performing code from reaching our production environment and bringing our “guaranteed 0% downtime” platform to its knees under the load of production volume? The answer lies in proper pre-production processes that validate our changes have not had substantial negative performance impacts.
In this article, I propose a workflow for optimizing .Net performance—measuring performance, diagnosing potential issues, and validating the efficacy of improvements. It’s an iterative process of discovery, profiling, refactoring, testing, benchmarking, and monitoring.
The sample application used in this article can be found on GitHub.
Performing code reviews is an essential part of maintaining some quality control over code before it reaches production. Code reviews allow your team members to read through your changes and, using their best judgment, approve or suggest changes to your work. This also helps the entire team keep abreast of all changes that are important to them.
However, code reviews take up the time of other engineers and can sometimes be less thorough than desired. The thoroughness of a review is rarely communicated to the team and so an approval can provide a false sense of security that the code is indeed production-ready.

Another failure point is that code reviews rarely include any kind of quantitative feedback. In other words, I can suggest method A will be faster or allocate less than method B, but I am unlikely to take the time to prove the quantitative impact of my assertion.
Finally, things simply get missed. Changes can be made in isolation from the consuming code and a reviewer may not be aware of the context in which a particular set of changes is being executed. For example, adding a simple one-time string concatenation may be fine, but if the consuming code is iterating over the changed code millions of times, then we may have just introduced some significant performance bottleneck.
In summary, code review is an indispensable part of the development process. It aids in maintaining style consistency, knowledge transfer, developer education and overall quality control. But, it should not be viewed as a method for ensuring that the implementation does not have any adverse or out-of-bounds performance impact.
The example application used in this blog post can be found on GitHub. It is a simple .NET Core web API application. The focus of this post is on the /people?name={name} route. This request will search our database of People and perform a fuzzy string match on the name, returning the entire list sorted from most to least similar. For the sake of simplicity, we will only implement one matching algorithm: Levenshtein Distance.
I recommend taking a quick look at the GitHub project. The call stack we’ll be focused on looks like:
Application Performance Management (APM) tools, such as Prefix and Retrace, can be used to identify poorly performing applications at a high level. This investigation enables local discovery of performance issues, and helps us narrow our focus before using a more detailed profiling utility.
In this example, I will use Prefix (a free tool from Stackify) to evaluate the distribution of work. This will help me understand what operations contribute the most to overall response time in the request. Perform these steps to get started.

As you can see from the above screenshot, the majority of the work is consumed by our .NET application code while a minor portion is consumed by I/O. From this I can quickly tell that this particular request has a risk of running as slow as 2.2 seconds on the first request and around 900 ms for subsequent requests. This is beyond the threshold of perceived user control. According to Jakob Nielson:
“new pages must display within 1 second for users to feel like they’re navigating freely”.
And it is significantly beyond the 0.1 second threshold of perceived instantaneity.
Prefix is a great tool for uncovering errors or performance issues in your local dev environment, but it can be difficult or impractical to reproduce production scenarios locally. Tools like Retrace are excellent at providing these same kinds of insights in remotely deployed environments.
Retrace will not only help detect production issues, but can also be used to discover issues in a staging environment so that bugs and performance problems are discovered early in the release cycle. Through log management, application monitoring, metrics and alerts you can quickly improve the quality of your release process. Retrace’s deployment tracking features also enable you to identify performance issues caused by recent changes to application code.
Now that we’ve identified—at a high level—an execution code path of interest, we can dive a little deeper by using a profiler. There are several different profiling options, most of which are personal preference. Visual Studio comes with a Performance Profiler, but there are alternatives such as JetBrains dotTrace and dotMemory. I should mention that the only profiler I was able to get to consistently work with .NET Core was Visual Studio Performance Profiler while debugging. In addition to the debugging profiler, Visual Studio comes with several other options, most of which do not yet work with .NET Core.
For a quick overview of the Visual Studio Profiler, I will defer to the official documentation.
Your approach to profiling should probably depend on the application type. For long-running applications with a constant and stable workload, you can sometimes get quick behavioral insights from just the CPU and memory charts. Before I dive into profiling the sample application, I’ll cover two common scenarios you may encounter while profiling.
The first example shows an app that executes a job every few seconds. You can see the memory being consumed by our application is continuing to grow and doesn’t appear to have any correlation to CPU usage. In this particular case, we’re seeing a memory leak where each unit of work in the application is leaking references and so they are not being cleaned up.
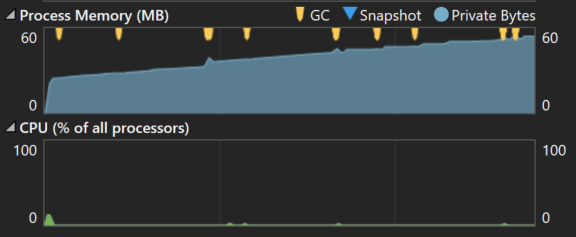
The next example shows an unbound and unthrottled event processing application. In other words, it processes real-time events as they occur.
We can see that while memory is increasing, so is CPU. This may be an indication that the application is just doing too much work, possibly in parallel. We may need to implement some kind of throttling. That could be an out-of-process mechanism—such as limiting the number of unacknowledged messages that should be delivered to a queue (in the case of AMQP). Or it could be an in-process mechanism—such as using a Semaphore. Or maybe we just need to scale our services to handle the load. But without diving in, there’s not much else we can infer from the graphs.
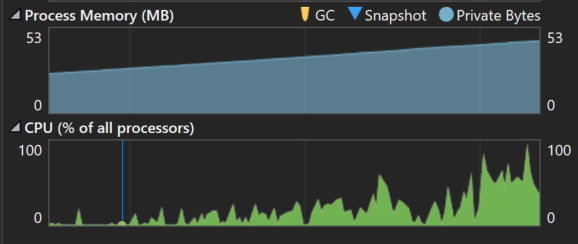
In our example application, there’s not much we can learn from the graphs themselves. However, since we’ve already identified a particular route of interest, we can set breakpoints to record memory and CPU usage around areas of interest. For this application, I set breakpoints in the service layer to capture the resource consumption of our search service.
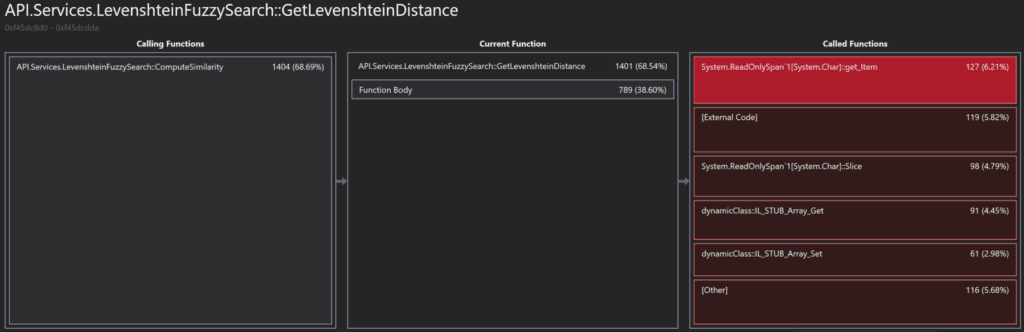
Below are the results from profiling the sample application. We can quickly see that we’re spending most of our CPU time in our fuzzy comparison function. This should not surprise us. Looking a little bit deeper we can see that 30% of the time spent within this function is spent in System.String.Substring(/*…*/).
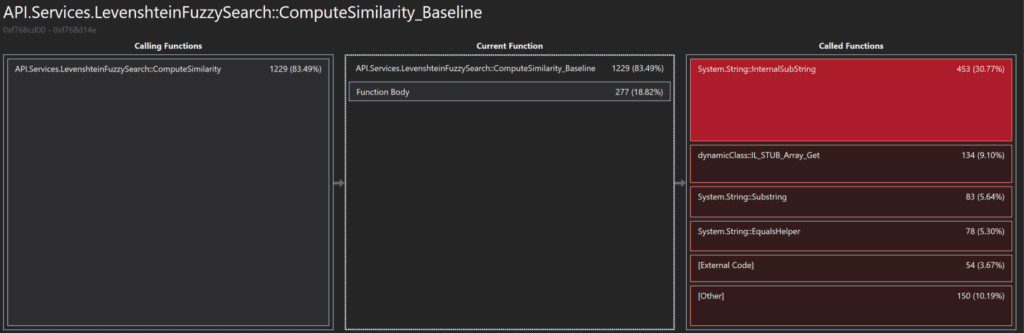
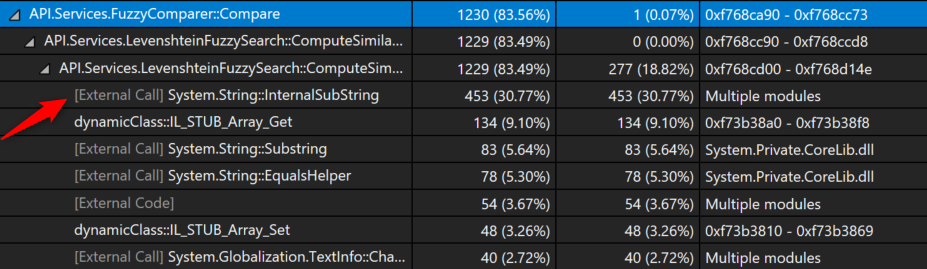
Historically, this wouldn’t have been our first choice for optimization. However, since the introduction of System.Span in C# 7.2, we now have a tool for improving some of these string parsing operations. Now that we have a candidate for optimization, the next step is to write benchmarks against the current implementation so that we can accurately quantify our improvements.
Benchmarking is a critical step when making performance improvements. Without it, we have no way to validate the impact of our changes.

I don’t think there is any argument that the best tool for writing benchmarks for .NET today is BenchmarkDotNet. Lots of people are using this tool today including the AspNetCore team.
I like to approach benchmarking in a very similar fashion to unit testing. For every project in the solution, I will create a corresponding benchmark project. The benchmark project will mirror the organization of the classes in the project under test. Each benchmark gets prefixed with the name of the system under test (e.g. Foo_Benchmarks.cs). This makes them easier to find later and distinguishable when locating types by name.
A benchmark application is just a console app that calls the benchmark runner. There are two approaches you can use in this entrypoint. The first is by explicitly listing the benchmarks you’d like to run:
class Program {
static void Main(string[] args) {
BenchmarkRunner.Run<Foo_Benchmarks>();
BenchmarkRunner.Run<Bar_Benchmarks>();
}
}
The second is a command line switcher that will provide you a prompt to specify the benchmark you’d like to run, assuming one was not provided as an argument. This is particularly useful if your project has a lot of benchmarks since running benchmarks can consume a great deal of time.
class Program {
static void Main(string[] args) {
var switcher = new BenchmarkSwitcher(new[] {
typeof(Foo_Benchmarks),
typeof(Bar_Benchmarks)
});
switcher.Run(args);
}
}

Diagnosers are one example of customizations you can use to improve your benchmarks. They can be attached to your benchmarks by decorating benchmark classes with attributes. My personal favorite is the MemoryDiagnoser, which provides cross-platform allocation and garbage collection detail.
The setup, teardown and parameter specification for benchmarks has a pretty similar interface to NUnit. You can create Global and Iterative Setup/Cleanup methods. You can also define compile-time constant parameters as members of the benchmark class or as an enumerable ParamsSource. For non compile-time constants, you will need to implement the IParam interface, which I have done in the example.
There are many more features in BenchmarkDotNet and I highly recommend reading through their documentation.
The example benchmark uses non compile-time constant parameters to create some random string data to be passed into our distance function. In the example, I generate random strings of lengths 10, 100, 1000, and 10000, and compare each of them against a randomly-generated string of length 100. You can take a look at the generated Markdown results here.
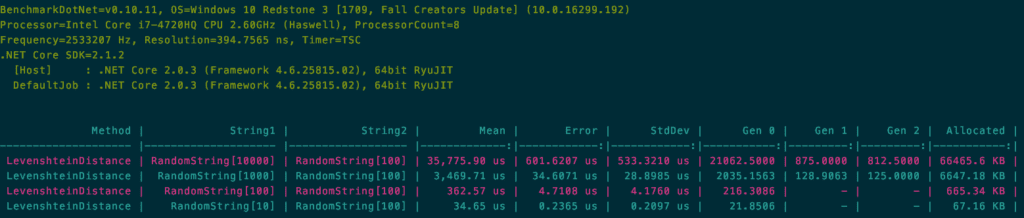
The first observation I would make is that the function’s execution time and allocations are linearly proportional to the size of the query parameter we are provided. What this means is that we have inadvertently created an attack vector for a bad actor. By not truncating the query string value, clients could invoke our API with long query strings in rapid succession. Based on the data, this would likely cause large CPU and memory spikes, potentially degrading our service or forcing us to scale.
The next observation is the memory allocation. In the case of a 1k character string, we will allocate over 6.6 MB just for comparing strings and 66 MB if we get a 10k character string!
Now that we understand the problem, we can implement a solution and validate the improvement with refactoring, unit tests, and benchmarking.
Before we start making optimizations, we need to make sure that we have unit tests around the system we intend to affect. Without tests, we may improve performance but we also risk breaking existing functionality. So the iterative process for making performance improvements should look like:

In our example application, I’m going to replace the use of string.Substring with the new Span<T> introduced in C# 7.2. For a great introductory on this new type, check out Jared Parson’s video on Channel 9. For a more in-depth look at Span and how you can use it today, check out this post by Adam Sitnik.
Span<T> allows us to work with contiguous memory in a type safe way. In the case of string parsing, this means we can iterate over the characters of a string and use an indexer to access characters without allocating a new string – string.Substring allocates new strings everytime.
I recommend taking a look at the commit to see the updated implementation using Span instead of Substring. The significant change was from this:
var a = str2.Substring(j - 1, 1); var b = str1.Substring(i - 1, 1); var cost = (a == b ? 0 : 1);
To this:
var a = str2.AsSpan().Slice(j - 1, 1)[0]; var b = str1.AsSpan().Slice(i - 1, 1)[0]; var cost = (a == b ? 0 : 1);
In order to evaluate the efficacy of our changes, we need to re-run our benchmarks against the new implementations, comparing them against the old. To do this, we can temporarily expose the old methods and tell BenchmarkDotNet that it should be our baseline for comparison:
[Benchmark] public int LevenshteinDistance() => _levenshteinFuzzySearch.ComputeSimilarity(String1.Value, String2.Value); [Benchmark(Baseline = true)] public int LevenshteinDistanceBaseline() => _levenshteinFuzzySearch.ComputeSimilarity_Baseline(String1.Value, String2.Value);
Now, running our benchmarks against the new and improved code gives us the following results:
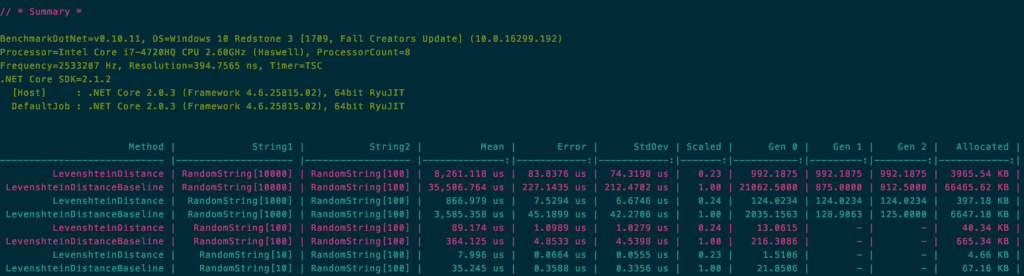
This shows that across the board, execution time decreased approximately 77% and allocations decreased by 94%. So, what does that mean in terms of user response time? Well, let’s take another look at our application in Prefix.
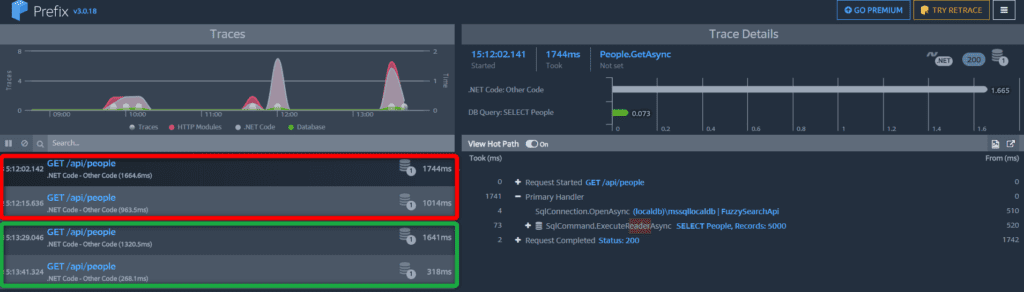
Here you can see both implementations running against the same dataset. We can see a slight improvement over the initial request, but what’s interesting is the 318 ms response time for subsequent requests. We’re now much closer to Nielson’s 0.1s target for perceived instantaneity on a fuzzy search across 5000 people records.
If we take a look at the profiler output for the new implementation, we can see how the breakdown has changed.
Here is a short list of a few common application performance problems I’ve encountered in the past:
At the end of the day, the quality of large-scale applications is limited by the quality of the processes that govern their development. Without proper pre-production processes, we will inevitably release poor-performing code to our users.
Through the use of pre-production tooling such as Prefix and Retrace on staging environments, we can gain quick insights into the performance impact of changes. Once we have identified possible issues, we can follow the procedure outlined above to correct performance problems before they bring down critical systems.
Stackify's APM tools are used by thousands of .NET, Java, PHP, Node.js, Python, & Ruby developers all over the world.
Explore Retrace's product features to learn more.
If you would like to be a guest contributor to the Stackify blog please reach out to stackify@stackify.com









