
Today we’re going to be talking about Strings in Java. If you write Java often, you know that a String is considered a first class object, even though it is not one of the eight primitive types. What you may not know is how to best handle Strings in production applications. To do this, you’ll need to understand how to internationalize/localize a String, manipulate very large Strings, or deeply understand String comparison rules. So let’s begin to… untangle this, shall we?
Internationalization (i18n) is the process of process of providing human-readable Strings in different languages, whereas localization (l10n) takes further geographical and cultural concerns into account. Internationalization is course whereas localization is granular. For example, the Strings “Choose your favorite color” and “Choose your favourite colour” are both English (i18n) but the former is used in the United States (en-US) and the latter is used in Great Britain (en-GB). (These codes are defined in “Tags for Identifying Languages”, as outlined in RFC 5646.)
Beyond standard messaging, i18n/l10n is also extremely important when representing dates/times and currency. The result of translating Strings into lengthier languages – say, German – can cause even the most meticulously planned UI to be completely redesigned, while adding support for double-byte character sets (i.e. Chinese, Japanese, Korean) can often require impactful changes throughout your entire stack.
That said, it obviously isn’t necessary to translate every String in your application – only the ones that humans will see. If for example, you have a server-side RESTful API written in Java, you would either a) look for a Accept-Language header on requests, apply settings as needed, then return a localized response or b) return a generally unaltered response, except for error cases that return an error code (that the front-end then uses to look up a translated String to show to the user). You’d choose b if the front-end is known and within your control. You’d choose if the raw response (even error responses) will be presented wholesale to the user, or if your API is available to unknown consumers and you aren’t sure how the responses will be used.
Java applications that present Strings directly to potentially non-English speaking humans will, of course, need to be translated. Consider again the example where a user is asked to enter his or her favorite color:
public class Main {
public static void main(String[] args) throws IOException {
Interviewer interviewer = new Interviewer();
System.out.println(interviewer.askColorQuestion());
Scanner scanner = new Scanner(System.in);
String color = scanner.nextLine();
System.out.println(interviewer.respondToColor(color));
scanner.close();
}
}
class Interviewer {
String askColorQuestion() {
return "Enter your favorite color:";
}
String respondToColor(String color) {
//You can switch on Strings since Java 7
switch(color) {
case "red":
return "Roses are red";
case "blue":
return "Violets are blue";
case "yellow":
return "Java is awesome";
default:
return "And so are you";
}
}
}
The Java IDE I use, Eclipse, provides a nice way to extract the Strings from the Interviewer class.
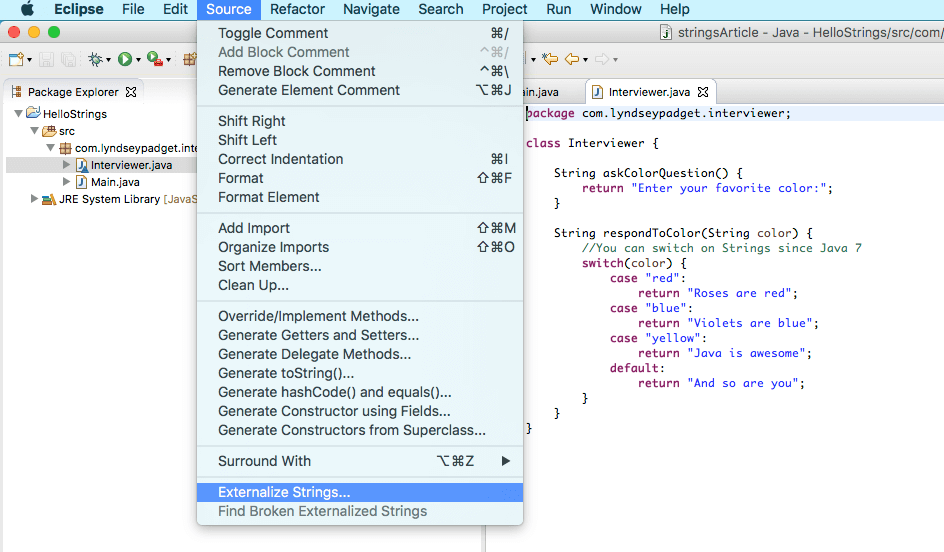
…and get them into a .properties file that I adjust to look like this:
Interviewer.color.question=Enter your favorite color: Interviewer.color.definition.1=red Interviewer.color.definition.2=blue Interviewer.color.definition.3=yellow Interviewer.color.response.1=Roses are red Interviewer.color.response.2=Violets are blue Interviewer.color.response.3=Java is awesome Interviewer.color.response.default=And so are you
Unfortunately, this process makes the Strings no longer constant as far as the switch statement is concerned.
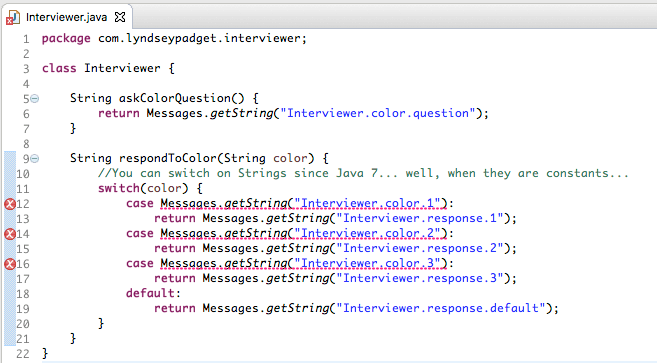
This is a bit unfortunate, but also an opportunity for us to anticipate that this application may – at some point in the future – need to handle more than just three colors. In the Messages class that Eclipse made for me, I add a method that will return any key/value pair given a prefix:
public static Map<String, String> getStrings(String prefix) {
Map<String, String> retVal = new HashMap<String, String>();
Enumeration<String> keys = RESOURCE_BUNDLE.getKeys();
while(keys.hasMoreElements()) {
String key = keys.nextElement();
if (key.startsWith(prefix)) {
retVal.put(key, RESOURCE_BUNDLE.getString(key));
}
}
return retVal;
}
And the Interviewer class uses this to more dynamically look up the user’s response and act on it:
class Interviewer {
String askColorQuestion() {
return Messages.getString("Interviewer.color.question");
}
String respondToColor(String color) {
Map<String, String> colorMap = Messages.getStrings("Interviewer.color.definition.");
for (String colorKey : colorMap.keySet()) {
String colorValue = colorMap.get(colorKey);
if (colorValue.equalsIgnoreCase(color)) {
String responseKey = colorKey.replace("definition", "response");
return Messages.getString(responseKey);
}
}
return Messages.getString("Interviewer.color.response.default");
}
}
The result is that the application can be easily translated. Based on some condition (like an environment variable or user request), you can use Java’s ResourceBundle to load a different properties file that serves up locale-specific messages.
Let’s suppose we want to factor the user’s favorite color into the system’s response, so that it tells the user, “Oh yes, ____ is also my favorite color!” You might break this up into two strings: “Oh yes, “ and “is also my favorite color!”. The result would look something like this:
Interviewer.color.response.part1=Oh yes, Interviewer.color.response.part2=is also my favorite color!
String respondToColor(String color) {
String part1 = Messages.getString("Interviewer.color.response.part1");
String part2 = Messages.getString("Interviewer.color.response.part2");
return part1 + color + " " + part2;
}
But this is bad news for i18n/l10n, because different languages often rearrange the order of nouns, verbs and adjectives. Some portions of the message may vary depending on the gender of a noun, the [past/present/future] tense in question, or who is receiving the message. It’s best to keep messages contiguous and succinct, replacing values only when needed. You could use one of String’s replace functions, but String.format is actually meant for this purpose:
Interviewer.color.response=Oh yes, %1$s is also my favorite color!
String respondToColor(String color) {
String format = Messages.getString("Interviewer.color.response");
return String.format(format, color);
}
Concatenation is perfectly fine when used to build small Strings meant for computer consumption. Building really large Strings? You’re going to need something better than concatenation there, too.
Strings are immutable in Java, meaning at their values can never truly change. This might not seem the case when you read the following code:
String favoriteColor = “red”; favoriteColor = “green”;
But you have to remember that the second assignment actually creates a new String (the value “green”), and reassigns favoriteColor (the reference) to that value. The old String (the value “red”) is orphaned and will eventually be garbage collected.
This is why concatenating Strings many, many, many times is a bad idea. Each time you concatenate, your application takes the hit of implicitly making a new String. Let’s look at an example where we want to read in long file of HTML colors, named “colorNames.dat”:
AliceBlue AntiqueWhite AntiqueWhite1 AntiqueWhite2 AntiqueWhite3 AntiqueWhite4 aquamarine1 aquamarine2 aquamarine4 azure1 azure2 azure3 azure4 beige bisque1 ...
The ColorList class reads each line of this file and makes one long String, complete with newline characters.
class ColorList {
String getAllColors(String filename) throws FileNotFoundException, IOException {
String retVal = "";
BufferedReader br = new BufferedReader(new InputStreamReader(this.getClass().getResourceAsStream(filename)));
for(String line; (line = br.readLine()) != null; ) {
retVal += line + "\n";
}
return retVal;
}
}
Note that the line inside of the for loop is actually creating four new Strings: One for the contents of the line, one for the newline character, one that combines them both, and one that appends that String to the current contents of retVal. To make matters worse, the old contents of retVal are then thrown away and replaced with this new String. No bueno!
The solution to this kind of problem is to use StringBuffer – or the newer, similarly-named StringBuilder. Both define themselves as “a mutable sequence of characters”, which solves the immutability problem. StringBuffer has existed since Java 1.0 and is thread-safe, meaning that threads sharing a “consistent and unchanging view of the source” can safely access and operate on the StringBuffer object. To keep things simple, and generally more performant, the documentation recommends using StringBuilder instead.
Introduced in Java 1.5, StringBuilder has the same interface as its predecessor but is not thread-safe because it doesn’t guarantee synchronization. Assuming you’re trying to build a very large String from a single source (such as a file or database), it’s usually sufficient to assign that job to a thread and walk away. StringBuilder is perfectly suitable for that job, and we prefer to use it over StringBuffer when we can:
class ColorList {
String getAllColors(String filename) throws FileNotFoundException, IOException {
StringBuilder retVal = new StringBuilder();
BufferedReader br = new BufferedReader(new InputStreamReader(this.getClass().getResourceAsStream(filename)));
for(String line; (line = br.readLine()) != null; ) {
retVal.append(line);
retVal.append("\n");
}
return retVal.toString();
}
}
If we crank the number of lines in our colorNames.dat file up to about 122,000 and then compare the concatenate and StringBuilder approaches from the main method:
public class Main {
public static void main(String[] args) throws IOException {
long startTime = System.nanoTime();
ColorList colorList = new ColorList();
String allColorNames = colorList.getAllColors("colorNames.dat");
System.out.print(allColorNames);
long endTime = System.nanoTime();
System.out.println("Took "+(endTime - startTime) + " ns");
}
}
We see that the concatenate approach takes about 50 seconds to execute, while the StringBuilder approach comes in at 0.7 seconds. That performance savings is huuuuge!
This is a simple and easy-to-measure example. If you’re looking to get a handle on your entire application’s performance problems, check out some beefier performance tools for Java applications.
Now that we’ve talked about String values and references, you’ll recall this classic piece of Java wisdom:
public class Main {
public static void main(String[] args) throws IOException {
String s1 = "red";
String s2 = "red";
if(s1.equals(s2)) {
System.out.println("s1 and s2 have equal values");
}
if(s1 == s2) {
System.out.println("s1 and s2 have equal references");
}
System.out.println("");
String s3 = "green";
String s4 = new String("green");
if(s3.equals(s4)) {
System.out.println("s3 and s4 have equal values");
}
if(s3 == s4) {
System.out.println("s3 and s4 have equal references");
}
System.out.println("\nDone!");
}
};
Running this yields:
s1 and s2 have equal values s1 and s2 have equal references s3 and s4 have equal values Done!
Although s1 and s2 are different variables, Java (in an effort to be efficient and helpful) realizes that s2 contains the same value as s1, so it points it to the same place in memory. This is why it considers them to be the same reference. By contrast, s4 has the same value as s3 but explicitly allocates a new location in memory for this value. When the time comes to see if they have the same reference, we see that they do not.
How Java manages its Strings’ references is generally best left to the compiler, but we must remain aware of it nonetheless. This is why, when we care about two Strings’ respective values, we must always use .equals, remembering that algorithms that search or sort Strings will rely on this method as well.
Consider the following example, containing two strings whose values are supposed to represent “dark blue” in French:
public class Main {
public static void main(String[] args) throws IOException {
String s1 = "bleu fonce";
String s2 = "Bleu fonce";
if(s1.equals(s2)) {
System.out.println("s1 and s2 have equal values");
}
else {
System.out.println("s1 and s2 do NOT have equal values");
}
}
};
The .equals method compares character-by-character, and notices that s1 and s2 are not equal due to case. The String class offers a convenient method called .equalsIgnoreCase that we can use to ignore the discrepancy. But what happens when we realize that there should actually be an accent on the final character (the correct word in French is “foncé”) but we want to continue accepting the old value and consider them both equal?
public class Main {
public static void main(String[] args) throws IOException {
String s1 = "bleu fonce";
String s2 = "Bleu foncé ";
if(s1.equalsIgnoreCase(s2)) {
System.out.println("s1 and s2 have equal values");
}
else {
System.out.println("s1 and s2 do NOT have equal values");
}
}
};
Once again, these Strings are not exactly equal because of the accent character and the whitespace. In this case, we need to specify a way to compare the Strings with a Comparator.
Comparators are particularly useful when you want to normalize Strings in a certain way before comparing them, but you don’t want that logic littered throughout your code.
First, we make a class that implements Comparator, which gives the equality logic a nice home. This particular Comparator does everything the default String Comparator would do, except it trims the Strings and compares them case insensitively.
public class CloseEnoughComparator implements Comparator<String> {
public int compare(String obj1, String obj2) {
if (obj1 == null) {
return -1;
}
if (obj2 == null) {
return 1;
}
if (obj1.equals( obj2 )) {
return 0;
}
String s1 = obj1.trim();
String s2 = obj2.trim();
return s1.compareToIgnoreCase(s2);
}
}
Then we change the main method to use the Comparator:
public class Main {
public static void main(String[] args) throws IOException {
String s1 = "bleu fonce";
String s2 = "Bleu foncé ";
Comparator<String> comparator = new CloseEnoughComparator();
if(comparator.compare(s1, s2) == 0) {
System.out.println("s1 and s2 have equal values");
}
else {
System.out.println("s1 and s2 do NOT have equal values");
}
}
};
Only one problem remains. Running the code above will still fail to consider these two Strings equal because of the accent character. Here’s where collation comes in.
Collation is the process of determining order (and thus, equality) given a particular ruleset. You may have heard the term collation used in the context of databases, where there may be a setting to establish the default collation for strings, money, or dates therein.
In Java, Collator is an abstract class that implements Comparator. That means that we could replace the Comparator Code in the main method, but I’ve opted to keep that interface intact and change the implementation of the compare method instead:
public class CloseEnoughComparator implements Comparator<String> {
public int compare(String obj1, String obj2) {
if (obj1 == null) {
return -1;
}
if (obj2 == null) {
return 1;
}
if (obj1.equals(obj2)) {
return 0;
}
Collator usCollator = Collator.getInstance(Locale.US);
usCollator.setStrength(Collator.PRIMARY);
return usCollator.compare(obj1, obj2);
}
}
A few noteworthy changes here:
The strength part is important. Collator provides four strengths from which to choose: PRIMARY, SECONDARY, TERTIARY, and IDENTICAL. The PRIMARY strength indicates that both whitespace and case can be ignored, and that – for comparison purposes – the difference between e and é can also be ignored. Experiment with different locales and strengths to learn more about how collation works, or check out Oracle’s Internationalization tutorial for a walk-through on Locales, Collators, Unicode, and more.
In Java, it’s easy to take Strings for granted because whatever we want to do “just works”. But can it work… better? Faster? Everywhere in the world?! The answer, of course, is yes, yes, and yes! It just takes a little bit of experimenting to more thoroughly understand how Strings work. That understanding will help you be prepared for whatever String-related requirements come your way in Java land.
Stackify's APM tools are used by thousands of .NET, Java, PHP, Node.js, Python, & Ruby developers all over the world.
Explore Retrace's product features to learn more.
If you would like to be a guest contributor to the Stackify blog please reach out to stackify@stackify.com









