
File manipulation is an incredibly common programming task with endless applications. It has two main sides: reading and writing. This post will focus on the “reading” bit, so if you’ve just googled “C# read file” and ended up here, search no more—we have the guide you need!
We’ll start by covering some prerequisites you need to follow, then dive right into the guide.
To follow along with the tutorial, we assume you have the following:
With that out of the way, let’s dig in!

Let’s start our guide with the simplest scenario: reading a whole file. Start by creating a new project of type “console application” using the method that’s most comfortable for you.
After that, create a file and place it in some easy location on your computer. For instance, if you’re on Linux, store it in your home directory. On Windows, I suggest creating a folder at the root of C: and placing the file there.
The contents of the file don’t matter; just write something. Make sure you create the file as a plain-text file. That is, don’t use text processors such as Microsoft Word or Apache Open Office Writer. Instead, use a simple text editor such as Notepad, Notepad++, or Gedit.
The file extension shouldn’t matter either, though using the .txt extension makes things easier on Windows—it’ll make Notepad automatically able to open the file.
Is your file ready to go? Great, you can now start writing some code. Remember that C# is an object-oriented language, so it shouldn’t come as a surprise that we’ll use a class to perform our file operations. The class is appropriately named “File,” and it lives in the System.IO namespace.
Start by adding “using System.IO;” to your list of using statements. Then, add the following line:
string fileContents = File.ReadAllText("C:\\files\\example.txt");The code calls the ReadAllText method on the File class, passing the path to the file as an argument. Notice the double backslashes? Since I’m on Windows, I have to use backslash as a path separator, but since it’s a special character inside a C# string, I need to escape it. If I was on Linux, I might have used a path like this: /home/carlosschults/files/example.txt. Of course, replace that place with the actual path to the file on your computer.
Anyway, my entire program currently looks like this:
using System.IO;
string fileContents = File.ReadAllText("C:\\files\\example.txt");If you’re using an older version of C#, before top-level statements were introduced, your code might look like this:
using System.IO;
internal class Program
{
private static void Main(string[] args)
{
string fileContents = File.ReadAllText("C:\\files\\example.txt");
}
}The end result is the same. As a next step, let’s display the contents of the file:
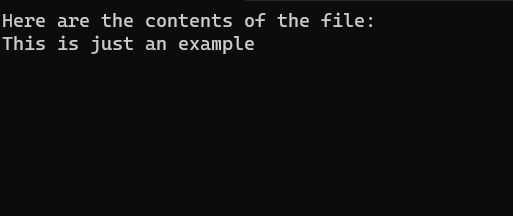
Console.WriteLine("Here are the contents of the file: ");
Console.WriteLine(fileContents);Finally, run the application. If you did everything right, you should see the contents of your file being displayed.
In the first example, you learned how to read a whole file and load its contents into a single string variable. Often, you need to do some kind of processing to a file that requires you to handle each of its lines separately—parsing a CSV file is an example that comes to mind.
Let’s learn how to do that. First, change your file so it has several lines. Here’s mine after the change:
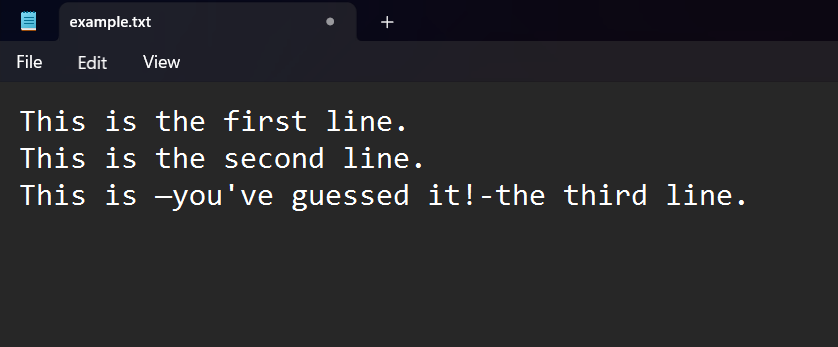
Now, let’s make two tiny changes to our original file reading code:
The new code should look like this:
string[] fileContents = File.ReadAllLines("C:\\files\\example.txt");You might be familiar with type inference—that is, using the var keyword instead of the type name when declaring a variable. In a normal situation, I’d use it, but I chose not to do it here in order to make the types as explicit as possible.
You now have an array of strings containing the lines of the file. Let’s use a for loop to iterate over those lines:
for (var i = 0; i < fileContents.Length; i++)
{
Console.WriteLine($"Line #{i + 1}: ");
Console.WriteLine(fileContents[i]);
Console.WriteLine();
}After running the application, you should now see something like this:
Line #1:
<Contents of the first line>
Line #2:
<Contents of the second line>
Line #n:
<Contents of the n-th line>Both the methods from the File class we’ve used so far are easy to understand and use. However, they can give you a headache if you come across large files. Those methods load the entirety of the file to memory, which means you can run out of memory with a large enough file.
OK, so how to proceed in such cases?
Let’s change the code again:
Here’s the new code:
IEnumerable<string> fileContents = File.ReadLines("C:\\files\\example.txt");
var index = 1;
foreach (string line in fileContents)
{
Console.WriteLine($"Line #{index}: ");
Console.WriteLine(line);
Console.WriteLine();
}If you run the code, you’ll see that the result is exactly the same. So, what has changed, if anything? The previous method, ReadAllLines, returned an array with all of the lines. So, you have the whole content of the file loaded in memory.
ReadLines, on the other hand, returns an IEnumerable. It doesn’t contain all lines loaded in memory. Instead, it’s more like a promise that if you request the next item, it will provide it to you as long as there are further items.
And how do you request the next item? You do that every time you iterate over the result using the foreach. The result is that the lines are being loaded one by one to memory.
Does all of the above sound a little fuzzy? I know, I understand it can be weird to wrap your head around those concepts. For now, do this:
If you try to open a file and it doesn’t exist on the path you provided, you’ll get an exception. So, how to handle this possibility?
An option would be to use the File.Exists method. Here’s our first example, updated so it validates the existence of the file:
string path = "C:\\files\\example404.txt";
if (File.Exists(path))
{
string fileContents = File.ReadAllText(path);
Console.WriteLine("Here are the contents of the file: ");
Console.WriteLine(fileContents);
}
else
{
Console.WriteLine("File wasn't found!");
}As you can see, here we use the method to check whether a file exists on that location. If it does, we display its contents. Otherwise, we show a fallback message.
This approach presents a problem, though. It’s a scenario called a race condition. You see, it’s possible that after our code has confirmed the existence of the file, some other process in the operating system deletes the file. Then, when the code reaches the point where it tries to read the file, it throws an exception anyway.
In this scenario, I’d recommend simply catching the exception and not bothering trying to validate the file’s existence:
try
{
string fileContents = File.ReadAllText(path);
Console.WriteLine("Here are the contents of the file: ");
Console.WriteLine(fileContents);
}
catch (FileNotFoundException ex)
{
// do something
}There are several other exceptions that can occur when reading files, all of them inheriting from System.IO.IOException class. Head to the .NET docs to learn more about the exceptions.
File manipulation is a staple of programming, and in this post, we’ve covered just the tip of the iceberg. You’ve learned:

Sometimes you don’t find what you’re looking for, and often the file you want to read isn’t there. Luckily, you’ve learned that you can either check for the presence of the file or simply don’t bother and handle the exception that may arise.
Before departing, I invite you to hang around at the Stackify blog and explore the .NET/C# posts we have there. They surely will be a great resource on your C# learning journey. Thanks for reading!
This post was written by Carlos Schults. Carlos is a consultant and software engineer with experience in desktop, web, and mobile development. Though his primary language is C#, he has experience with a number of languages and platforms. His main interests include automated testing, version control, and code quality.
Stackify's APM tools are used by thousands of .NET, Java, PHP, Node.js, Python, & Ruby developers all over the world.
Explore Retrace's product features to learn more.
If you would like to be a guest contributor to the Stackify blog please reach out to stackify@stackify.com










