
One of the major developments in software design and delivery over the last few years has been a movement away from monolith applications towards microservices. One of the sticking points I’ve seen on numerous microservice applications is logging. There are some unique challenges with microservice logging that need to be addressed. In this article, we’ll look at how we can make logging in a microservice as painless as in a monolith.
There are lots of definitions of microservices out there, but this is the one I like.
Microservices: A top-level software design favoring small, loosely-connected services that maintain data autonomy and are independently deployable.
Breaking this down using microservices is a high-level decision. It isn’t a pattern you apply only to one part of your application but must be a global decision. When using microservices, we create a number of smaller applications that have very limited functionality. For instance, we might have a service whose entire responsibility is to act as a wrapper to talk to an external API. The services should be loosely-connected: no direct calls between services or excessive cross-talk between services. The services should each have their own data storage solution that isn’t shared with another service. This means absolutely no integrating at the database level! Finally, there should be no dependencies between services at deployment time.
Defining boundaries between services in a cluster of microservices is a difficult problem. There are lots of ideas around it, but most of them revolve around domain-driven design.
While there are lots of advantages to a microservices approach, there are also drawbacks. Monoliths are deployed as a single entity to one or more servers, each of which gets the same code. This single deployment is both a curse and a blessing. Single deployments mean that you have fewer moving pieces in the build and deployment pipeline. There are no concerns about transporting data between multiple applications or figuring out the boundaries for these applications. The advantage most important for this article is that logging lives in just one location.
Logging is a perfect example of a cross-cutting concern: code that needs to span numerous modules at different levels of the code base. When we split our application into silos, logging is also split over every service.
An oft-touted advantage of microservices is that each service can be written using an appropriate technology. A component that does a great deal of math might not be as efficient written in JavaScript as in Go. Microservices allow you to select a technology of best fit for each component. Often each microservice is built by a team that specializes in the technology used in that service. Enforcing a single logging technology flies in the face of the microservice mentality. However, this is a time when pulling back on academic perfection in favor of pragmatism is justifiable.

A single logging technology gives us one place to go for logs, regardless of which service originates the log message. If we’re trying to hunt down a network problem, we don’t want to have to jump around a bunch of log files located all over the place to see which services have been impacted. Ideally, we want to have a one-stop-shop that allows searching, sorting, and projecting log information from many dozens of services. The technologies that allow this, log aggregators, tend to have connectors for numerous languages. For instance, Stackify Retrace has connectors for Java, .NET, PHP, Ruby and Node.js out of the box, as well as a Restful API that unlocks almost every other language.
Errors may span multiple microservices, so logging as our best tool for tracking down errors should also span them too.
A single user interaction in a microservice architecture may span many services. Being able to follow a user interaction becomes much easier if you have a logging tool that lets you use an advanced query language to search, project, and aggregate. Logging in aggregate can also be very useful. Queries like this are super-valuable: “what percentage of requests to service X result in errors?”, or “at what time of day do we see the most load on the system”, or even “what’s the average time a request spends in service X”.
Of course, there are a whole lot of log aggregators out there, and picking one that has a rich query language is a good differentiator. Another aspect to consider is how easy it is to visualize the data once you’ve written a query for it. A good graph will give information at a glance that is difficult to parse from a log message.
Below is an example of a dashboard from Retrace showing a number of key metrics, some of which are taken from log searches.
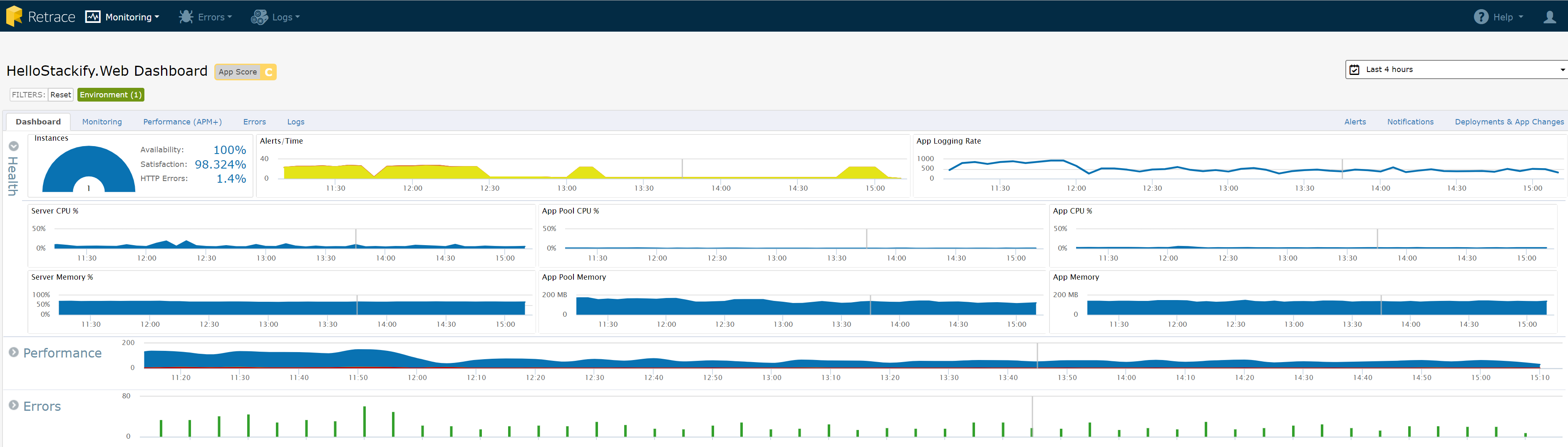
When a customer contacts you with a problem they’ve had on your application, it is really nice to be able to quickly find what went wrong. One method of doing so in a microservice application is to include a correlation or transaction Id in each message. Populate this field with an Id taken from the initiating event. Consider a scenario where a user creates an account. This may trigger actions in the user service, customer loyalty service, and billing service.
By having a unique identifier that is logged out by each of these services as they process a message, finding the flow of user creation becomes easy. All that is needed is to pop the unique id into the log aggregator search engine, and outcomes all the log messages related to this transaction. You could even present the user with this correlation id should something go wrong, so they have a reference number to quote when talking to your support organization; this is even more useful if you happen to be the support organization.
It is much more common for me to wish I had more information logged than less. There are obviously some performance and storage considerations around logging too much, but logging too little may lose you key pieces of information forever. Including context information in your log messages increase the chances that you’ll be able to track down problems. As an example, I typically enhance my log messages with information like:
Consider carefully what information would be useful in debugging problems and err on the side of including too much. If you’re using a logging framework that supports structured logging (which his brilliant), then you can put all this information in the log message properties and not junk up your actual messages.
Synchronizing clocks across multiple machines in a distributed system is a surprisingly difficult problem. In a monolithic application, you can rely on timestamps in the logs being in the correct order because everything happens on a single machine with a single time source. In distributed systems, clocks on different systems may be slightly out of sync. Network Time Protocol (NTP) can be used to keep clocks in close sync, but it is not exact. For logging purposes, NTP resolution is usually sufficient, but there can be times where your logs show a message being processed before it has been sent. Don’t worry – your system isn’t experimenting with time travel as a precursor to sending a terminator back in time to kill your grandparents, it is just that the clocks have drifted.
There are solutions to event ordering such as Lamport or vector clocks when event ordering is of some importance. I’m not aware of any log aggregators that make use of anything other than a timestamp to order messages.
The independent nature of each service in a microservices mesh is supposed to prevent failures in one service from overflowing and taking out every other service. By using a single logging technology, we’ve introduced a single point of failure. Remember the rather lengthy outage Azure suffered earlier this year due to a power surge at their South Central data center? During that outage, their logging aggregator, App Insights, was unavailable. We certainly don’t want something as tangential to the primary purpose of our application to render it unusable.
It is sensible to ensure that failures in logging can be handled. Maintaining a local ring cache of log messages in case of logging failures, or having a fallback service that just retains the data until logging is restored, are both effective strategies to handle logging failures. No matter the selected solution, it is important to consider failures carefully.
There is no shortage of legislation these days that dictates how you should handle processing people’s data. Even if you’re not in Europe, GDPR can apply to your product or your customers. The key idea in most legislation is “don’t lose personal data” and “be able to delete personal data upon request”. Logging personally-identifiable information is problematic on both those fronts. Log data is usually considered of lower importance than application data, but losing it exposes the same details as losing the actual database. If the log data doesn’t have the personal information in it in the first place, then that makes losing the data far less problematic.
The right to be forgotten is an equally difficult problem. Removing log messages containing data that needs to be deleted when forgetting a user requires modifying log data. Typically we’d like log data to be immutable, and we’d lose that if we had to delete random log messages.
I like to annotate my messages with information about what fields can be logged. When destructuring the message for logging, replace these values with redacted versions as part of the logging framework.
Following the suggestions in this article will give you a logging experience as if you were building a monolith, but still retain the vast advantages of microservices. Microservices can be a scalable way to build large, complex systems, and are especially good for enabling scaling teams.
Start sending all errors and logs to Retrace and view them in the Retrace Logs Dashboard. Sign up for a free, two week trial of Retrace today.
Stackify's APM tools are used by thousands of .NET, Java, PHP, Node.js, Python, & Ruby developers all over the world.
Explore Retrace's product features to learn more.
If you would like to be a guest contributor to the Stackify blog please reach out to stackify@stackify.com









